Table of Contents
In previous chapters, this book described the scheduling subsystem as the creator of the impression that threads execute in parallel. The memory management subsystem, on the other hand, creates the impression that there is enough physical memory for the kernel and that userspace tasks have the entire address space only for themselves.
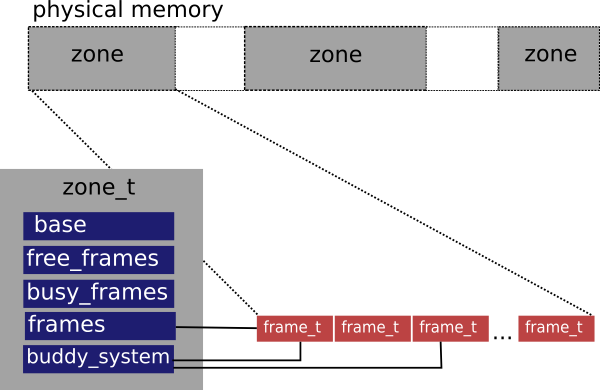
HelenOS represents continuous areas of physical memory in structures called frame zones (abbreviated as zones). Each zone contains information about the number of allocated and unallocated physical memory frames as well as the physical base address of the zone and number of frames contained in it. A zone also contains an array of frame structures describing each frame of the zone and, in the last, but not the least important, front, each zone is equipped with a buddy system that faciliates effective allocation of power-of-two sized block of frames.
This organization of physical memory provides good preconditions
for hot-plugging of more zones. There is also one currently unused zone
attribute: flags. The attribute could be used to give a
special meaning to some zones in the future.
The zones are linked in a doubly-linked list. This might seem a bit ineffective because the zone list is walked everytime a frame is allocated or deallocated. However, this does not represent a significant performance problem as it is expected that the number of zones will be rather low. Moreover, most architectures merge all zones into one.
Every physical memory frame in a zone, is described by a structure that contains number of references and other data used by buddy system.
The frame allocator satisfies kernel requests to allocate power-of-two sized blocks of physical memory. Because of zonal organization of physical memory, the frame allocator is always working within a context of a particular frame zone. In order to carry out the allocation requests, the frame allocator is tightly integrated with the buddy system belonging to the zone. The frame allocator is also responsible for updating information about the number of free and busy frames in the zone.
Allocation / deallocation. Upon allocation request via function frame_alloc(),
the frame allocator first tries to find a zone that can satisfy the
request (i.e. has the required amount of free frames). Once a suitable
zone is found, the frame allocator uses the buddy allocator on the
zone's buddy system to perform the allocation. During deallocation,
which is triggered by a call to frame_free(), the frame
allocator looks up the respective zone that contains the frame being
deallocated. Afterwards, it calls the buddy allocator again, this time
to take care of deallocation within the zone's buddy system.
In the buddy system, the memory is broken down into power-of-two sized naturally aligned blocks. These blocks are organized in an array of lists, in which the list with index i contains all unallocated blocks of size 2i. The index i is called the order of block. Should there be two adjacent equally sized blocks in the list i (i.e. buddies), the buddy allocator would coalesce them and put the resulting block in list i + 1, provided that the resulting block would be naturally aligned. Similarily, when the allocator is asked to allocate a block of size 2i, it first tries to satisfy the request from the list with index i. If the request cannot be satisfied (i.e. the list i is empty), the buddy allocator will try to allocate and split a larger block from the list with index i + 1. Both of these algorithms are recursive. The recursion ends either when there are no blocks to coalesce in the former case or when there are no blocks that can be split in the latter case.
This approach greatly reduces external fragmentation of memory and helps in allocating bigger continuous blocks of memory aligned to their size. On the other hand, the buddy allocator suffers increased internal fragmentation of memory and is not suitable for general kernel allocations. This purpose is better addressed by the slab allocator.

The buddy allocator is, in fact, an abstract framework which can be easily specialized to serve one particular task. It knows nothing about the nature of memory it helps to allocate. In order to beat the lack of this knowledge, the buddy allocator exports an interface that each of its clients is required to implement. When supplied with an implementation of this interface, the buddy allocator can use specialized external functions to find a buddy for a block, split and coalesce blocks, manipulate block order and mark blocks busy or available.
Data organization. Each entity allocable by the buddy allocator is required to
contain space for storing block order number and a link variable
used to interconnect blocks within the same order.Whatever entities are allocated by the buddy allocator, the
first entity within a block is used to represent the entire block.
The first entity keeps the order of the whole block. Other entities
within the block are assigned the magic value
BUDDY_INNER_BLOCK. This is especially important
for effective identification of buddies in a one-dimensional array
because the entity that represents a potential buddy cannot be
associated with BUDDY_INNER_BLOCK (i.e. if it
is associated with BUDDY_INNER_BLOCK then it is
not a buddy).
The majority of memory allocation requests in the kernel is for small, frequently used data structures. The basic idea behind the slab allocator is that commonly used objects are preallocated in continuous areas of physical memory called slabs[7]. Whenever an object is to be allocated, the slab allocator returns the first available item from a suitable slab corresponding to the object type[8]. Due to the fact that the sizes of the requested and allocated object match, the slab allocator significantly reduces internal fragmentation.
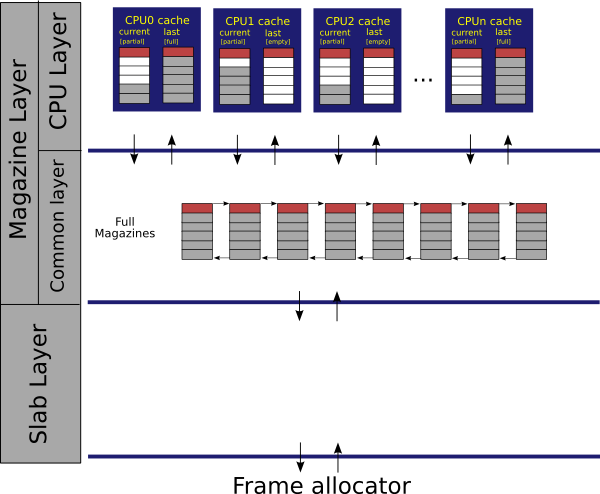
Slabs of one object type are organized in a structure called slab cache. There are ususally more slabs in the slab cache, depending on previous allocations. If the the slab cache runs out of available slabs, new slabs are allocated. In order to exploit parallelism and to avoid locking of shared spinlocks, slab caches can have variants of processor-private slabs called magazines. On each processor, there is a two-magazine cache. Full magazines that are not part of any per-processor magazine cache are stored in a global list of full magazines.
Each object begins its life in a slab. When it is allocated from there, the slab allocator calls a constructor that is registered in the respective slab cache. The constructor initializes and brings the object into a known state. The object is then used by the user. When the user later frees the object, the slab allocator puts it into a processor private magazine cache, from where it can be precedently allocated again. Note that allocations satisfied from a magazine are already initialized by the constructor. When both of the processor cached magazines get full, the allocator will move one of the magazines to the list of full magazines. Similarily, when allocating from an empty processor magazine cache, the kernel will reload only one magazine from the list of full magazines. In other words, the slab allocator tries to keep the processor magazine cache only half-full in order to prevent thrashing when allocations and deallocations interleave on magazine boundaries. The advantage of this setup is that during most of the allocations, no global spinlock needs to be held.
Should HelenOS run short of memory, it would start deallocating objects from magazines, calling slab cache destructor on them and putting them back into slabs. When a slab contanins no allocated object, it is immediately freed.
The slab allocator is closely modelled after [Bonwick01] with the following exceptions:
empty slabs are immediately deallocated and
empty magazines are deallocated when not needed.
The following features are not currently supported but would be easy to do:
- cache coloring and
- dynamic magazine grow (different magazine sizes are already supported, but the allocation strategy would need to be adjusted).
The following two paragraphs summarize and complete the
description of the slab allocator operation (i.e.
slab_alloc() and slab_free()
functions).
Allocation. Step 1. When an allocation request comes, the slab allocator checks availability of memory in the current magazine of the local processor magazine cache. If the available memory is there, the allocator just pops the object from magazine and returns it.Step 2. If the current magazine in the processor magazine cache is empty, the allocator will attempt to swap it with the last magazine from the cache and return to the first step. If also the last magazine is empty, the algorithm will fall through to Step 3.Step 3. Now the allocator is in the situation when both magazines in the processor magazine cache are empty. The allocator reloads one magazine from the shared list of full magazines. If the reload is successful (i.e. there are full magazines in the list), the algorithm continues with Step 1.Step 4. In this fail-safe step, an object is allocated from the conventional slab layer and a pointer to it is returned. If also the last magazine is full,
Deallocation. Step 1. During a deallocation request, the slab allocator checks if the current magazine of the local processor magazine cache is not full. If it is, the pointer to the objects is just pushed into the magazine and the algorithm returns.Step 2. If the current magazine is full, the allocator will attempt to swap it with the last magazine from the cache and return to the first step. If also the last magazine is empty, the algorithm will fall through to Step 3.Step 3. Now the allocator is in the situation when both magazines in the processor magazine cache are full. The allocator tries to allocate a new empty magazine and flush one of the full magazines to the shared list of full magazines. If it is successfull, the algoritm continues with Step 1.Step 4. In case of low memory condition when the allocation of empty magazine fails, the object is moved directly into slab. In the worst case object deallocation does not need to allocate any additional memory.
Virtual memory is essential for an operating system because it makes several things possible. First, it helps to isolate tasks from each other by encapsulating them in their private address spaces. Second, virtual memory can give tasks the feeling of more memory available than is actually possible. And third, by using virtual memory, there might be multiple copies of the same program, linked to the same addresses, running in the system. There are at least two known mechanisms for implementing virtual memory: segmentation and paging. Even though some processor architectures supported by HelenOS[9] provide both mechanisms, the kernel makes use solely of paging.
In a paged virtual memory, the entire virtual address space is divided into small power-of-two sized naturally aligned blocks called pages. The processor implements a translation mechanism, that allows the operating system to manage mappings between set of pages and set of identically sized and identically aligned pieces of physical memory called frames. In a result, references to continuous virtual memory areas don't necessarily need to reference continuos area of physical memory. Supported page sizes usually range from several kilobytes to several megabytes. Each page that takes part in the mapping is associated with certain attributes that further desribe the mapping (e.g. access rights, dirty and accessed bits and present bit).
When the processor accesses a page that is not present (i.e. its present bit is not set), the operating system is notified through a special exception called page fault. It is then up to the operating system to service the page fault. In HelenOS, some page faults are fatal and result in either task termination or, in the worse case, kernel panic[10], while other page faults are used to load memory on demand or to notify the kernel about certain events.
The set of all page mappings is stored in a memory structure called page tables. Some architectures have no hardware support for page tables[11] while other processor architectures[12] understand the whole memory format thereof. Despite all the possible differences in page table formats, the HelenOS VAT subsystem[13] unifies the page table operations under one programming interface. For all parts of the kernel, three basic functions are provided:
page_mapping_insert(),page_mapping_find()andpage_mapping_remove().
The page_mapping_insert() function is used to
introduce a mapping for one virtual memory page belonging to a
particular address space into the page tables. Once the mapping is in
the page tables, it can be searched by page_mapping_find()
and removed by page_mapping_remove(). All of these
functions internally select the page table mechanism specific functions
that carry out the self operation.
There are currently two supported mechanisms: generic 4-level hierarchical page tables and global page hash table. Both of the mechanisms are generic as they cover several hardware platforms. For instance, the 4-level hierarchical page table mechanism is used by amd64, ia32, mips32 and ppc32, respectively. These architectures have the following page table format: 4-level, 2-level, TLB-only and hardware hash table, respectively. On the other hand, the global page hash table is used on ia64 that can be TLB-only or use a hardware hash table. Although only two mechanisms are currently implemented, other mechanisms (e.g. B+tree) can be easily added.
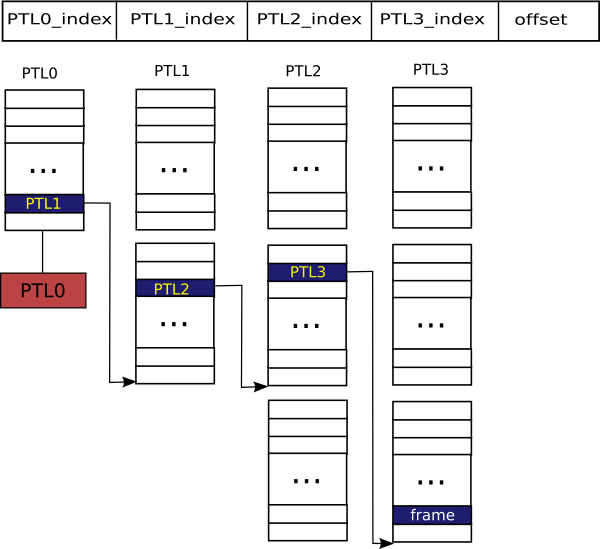
Hierarchical 4-level page tables are generalization of the frequently used hierarchical model of page tables. In this mechanism, each address space has its own page tables. To avoid confusion in terminology used by hardware vendors, in HelenOS, the root level page table is called PTL0, the two middle levels are called PTL1 and PTL2, and, finally, the leaf level is called PTL3. All architectures using this mechanism are required to use PTL0 and PTL3. However, the middle levels can be left out, depending on the hardware hierarchy or structure of software-only page tables. The genericity is achieved through a set of macros that define transitions from one level to another. Unused levels are optimised out by the compiler.
Implementation of the global page hash table was encouraged by 64-bit architectures that can have rather sparse address spaces. The hash table contains valid mappings only. Each entry of the hash table contains an address space pointer, virtual memory page number (VPN), physical memory frame number (PFN) and a set of flags. The pair of the address space pointer and the virtual memory page number is used as a key for the hash table. One of the major differences between the global page hash table and hierarchical 4-level page tables is that there is only a single global page hash table in the system while hierarchical page tables exist per address space. Thus, the global page hash table contains information about mappings of all address spaces in the system.
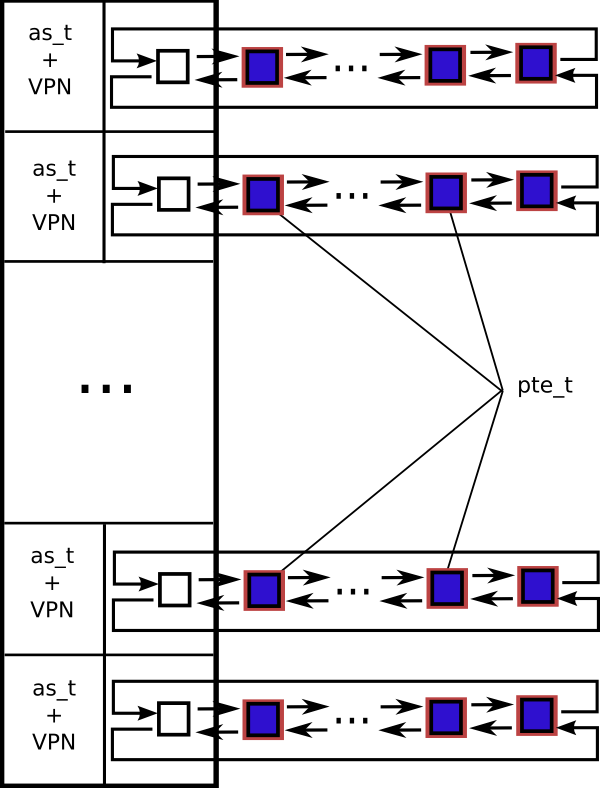
The global page hash table mechanism uses the generic hash table type as described in the chapter dedicated to data structures earlier in this book.
Due to the extensive overhead of several extra memory accesses during page table lookup that are necessary on every instruction, modern architectures deploy fast assotiative cache of recelntly used page mappings. This cache is called TLB - Translation Lookaside Buffer - and is present on every processor in the system. As it has been already pointed out, TLB is the only page translation mechanism for some architectures.
The operating system is responsible for keeping TLB consistent with the page tables. Whenever mappings are modified or purged from the page tables, or when an address space identifier is reused, the kernel needs to invalidate the respective contents of TLB. Some TLB types support partial invalidation of their content (e.g. ranges of pages or address spaces) while other types can be invalidated only entirely. The invalidation must be done on all processors for there is one TLB per processor. Maintaining TLB consistency on multiprocessor configurations is not as trivial as it might look from the first glance.
The remote TLB invalidation is called TLB shootdown. HelenOS uses a simplified variant of the algorithm described in [Black89].
TLB shootdown is performed in three phases.
Phase 1. The initiator clears its TLB flag and locks the global TLB spinlock. The request is then enqueued into all other processors' TLB shootdown message queues. When the TLB shootdown message queue is full on any processor, the queue is purged and a single request to invalidate the entire TLB is stored there. Once all the TLB shootdown messages were dispatched, the initiator sends all other processors an interrupt to notify them about the incoming TLB shootdown message. It then spins until all processors accept the interrupt and clear their TLB flags.
Phase 2. Except for the initiator, all other processors are spining on the TLB spinlock. The initiator is now free to modify the page tables and purge its own TLB. The initiator then unlocks the global TLB spinlock and sets its TLB flag.
Phase 3. When the spinlock is unlocked by the initiator, other processors are sequentially granted the spinlock. However, once they manage to lock it, they immediately release it. Each processor invalidates its TLB according to messages found in its TLB shootdown message queue. In the end, each processor sets its TLB flag and resumes its previous operation.
In HelenOS, address spaces are objects that encapsulate the following items:
address space identifier,
page table PTL0 pointer and
a set of mutually disjunctive address space areas.
Address space identifiers will be discussed later in this section. The address space contains a pointer to PTL0, provided that the architecture uses per address space page tables such as the hierarchical 4-level page tables. The most interesting component is the B+tree of address space areas belonging to the address space.
Because an address space can be composed of heterogenous mappings such as userspace code, data, read-only data and kernel memory, it is further broken down into smaller homogenous units called address space areas. An address space area represents a continuous piece of userspace virtual memory associated with common flags. Kernel memory mappings do not take part in address space areas because they are hardwired either into TLBs or page tables and are thus shared by all address spaces. The flags are a combination of:
AS_AREA_READ,AS_AREA_WRITE,AS_AREA_EXECandAS_AREA_CACHEABLE.
The AS_AREA_READ flag is implicit and cannot
be removed. The AS_AREA_WRITE flag denotes a
writable address space area and the AS_AREA_EXEC is
used for areas containing code. The combination of
AS_AREA_WRITE and AS_AREA_EXEC
is not allowed. Some architectures don't differentiate between
executable and non-executable mappings. In that case, the
AS_AREA_EXEC has no effect on mappings created for
the address space area in the page tables. If the flags don't have
AS_AREA_CACHEABLE set, the page tables content of
the area is created with caching disabled. This is useful for address
space areas containing memory of some memory mapped device.
Address space areas can be backed by a backend that provides virtual functions for servicing page faults that occur within the address space area, releasing memory allocated by the area and sharing the area. Currently, there are three backends supported by HelenOS: anonymous memory backend, ELF image backend and physical memory backend.
Anonymous memory backend. Anonymous memory is memory that has no predefined contents such as userspace stack or heap. Anonymous address space areas are backed by memory allocated from the frame allocator. Areas backed by this backend can be resized as long as they are not shared.
ELF image backend. Areas backed by the ELF backend are composed of memory that can be either initialized, partially initialized or completely anonymous. Initialized portions of ELF backend address space areas are those that are entirely physically present in the executable image (e.g. code and initialized data). Anonymous portions are those pages of the bss section that exist entirely outside the executable image. Lastly, pages that don't fit into the previous two categories are partially initialized as they are both part of the image and the bss section. The initialized portion does not need any memory from the allocator unless it is writable. In that case, pages are duplicated on demand during page fault and memory for the copy is allocated from the frame allocator. The remaining two parts of the ELF always require memory from the frame allocator. Non-shared address space areas backed by the ELF image backend can be resized.
Physical memory backend. Physical memory backend is used by the device drivers to access physical memory. No additional memory needs to be allocated on a page fault in this area and when sharing this area. Areas backed by this backend cannot be resized.
Address space areas can be shared provided that their backend
supports sharing[14]. When the kernel calls as_area_share(), a
check is made to see whether the area is already being shared. If the
area is already shared, it contains a pointer to the share info
structure. The pointer is then simply copied into the new address
space area and a reference count in the share info structure is
incremented. Otherwise a new address space share info structure needs
to be created. The backend is then called to duplicate the mapping of
pages for which a frame is allocated. The duplicated mapping is stored
in the share info structure B+tree called pagemap.
Note that the reference count of the frames put into the
pagemap must be incremented in order to avoid a race condition.
If the originating address space area had been destroyed before the pagemap
information made it to the page tables of other address spaces that take part in
the sharing, the reference count of the respective frames
would have dropped to zero and some of them could have been allocated again.
When a page fault is encountered in the address space area, the
address space page fault handler, as_page_fault(),
invokes the corresponding backend page fault handler to resolve the
situation. The backend might either confirm the page fault or perform
a remedy. In the non-shared case, depending on the backend, the page
fault can be remedied usually by allocating some memory on demand or
by looking up the frame for the faulting translation in the ELF
image.
Shared address space areas need to consider the
pagemap B+tree. First they need to make sure
whether the mapping is not present in the pagemap.
If it is there, then the frame reference count is increased and the
page fault is resolved. Otherwise the handler proceeds similarily to
the non-shared case. If it allocates a physical memory frame, it must
increment its reference count and add it to the
pagemap.
Modern processor architectures optimize TLB utilization by associating TLB entries with address spaces through assigning identification numbers to them. In HelenOS, the term ASID, originally taken from the mips32 terminology, is used to refer to the address space identification number. The advantage of having ASIDs is that TLB does not have to be invalidated on thread context switch as long as ASIDs are unique. Unfortunately, architectures supported by HelenOS use all different widths of ASID numbers[15] out of which none is sufficient. The amd64 and ia32 architectures cannot make use of ASIDs as their TLB doesn't recognize such an abstraction. Other architectures have support for ASIDs, but for instance ppc32 doesn't make use of them in the current version of HelenOS. The rest of the architectures does use ASIDs. However, even on the ia64 architecture, the minimal supported width of ASID[16] is insufficient to provide a unique integer identifier to all address spaces that might hypothetically coexist in the running system. The situation on mips32 is even worse: the architecture has only 256 unique identifiers.
To mitigate the shortage of ASIDs, HelenOS uses the following strategy. When the system initializes, a FIFO queue[17] is created and filled with all available ASIDs. Moreover, every address space remembers the number of processors on which it is active. Address spaces that have a valid ASID and that are not active on any processor are appended to the list of inactive address spaces with valid ASID. When an address space needs to be assigned a valid ASID, it first checks the FIFO queue. If it contains at least one ASID, the ASID is allocated. If the queue is empty, an ASID is simply stolen from the first address space in the list. In that case, the address space that loses the ASID in favor of another address space, is removed from the list. After the new ASID is purged from all TLBs, it can be used by the address space. Note that this approach works due to the fact that the number of ASIDs is greater than the maximal number of processors supported by HelenOS and that there can be only one active address space per processor. In other words, when the FIFO queue is empty, there must be address spaces that are not active on any processor.
[7] Slabs are in fact blocks of physical memory frames allocated from the frame allocator.
[8] The mechanism is rather more complicated, see the next paragraph.
[9] ia32 has full-fledged segmentation.
[10] Such a condition would be either caused by a hardware failure or a bug in the kernel.
[11] On mips32, TLB-only model is used and the operating system is responsible for managing software defined page tables.
[12] Like amd64 and ia32.
[13] Virtual Address Translation subsystem.
[14] Which is the case for all currently supported backends.
[15] amd64 and ia32 don't use similar abstraction at all, mips32 has 8-bit ASIDs and ia64 can have ASIDs between 18 to 24 bits wide.
[16] RID in ia64 terminology.
[17] Note that architecture-specific measures are taken to avoid too large FIFO queue. For instance, seven consecutive ia64 RIDs are grouped to form one HelenOS ASID.