Table of Contents
One of the key aims of the operating system is to create and support the impression that several activities are executing contemporarily. This is true for both uniprocessor as well as multiprocessor systems. In the case of multiprocessor systems, the activities are truly happening in parallel. The scheduler helps to materialize this impression by planning threads on as many processors as possible and, when this strategy reaches its limits, by quickly switching among threads executing on a single processor.
The term context refers to the set of processor resources that define the current state of the computation or the environment and the kernel understands it in several more or less narrow sences:
synchronous register context,
asynchronous register context,
FPU context and
memory management context.
The most narrow sense refers to the the synchronous register context. It includes all the preserved registers as defined by the architecture. To highlight some, the program counter and stack pointer take part in the synchronous register context. These registers must be preserved across a procedure call and during synchronous context switches.
The next type of the context understood by the kernel is the asynchronous register context. On an interrupt, the interrupted execution flow's state must be guaranteed to be eventually completely restored. Therefore the interrupt context includes, among other things, the scratch registers as defined by the architecture. As a special optimization and if certain conditions are met, it need not include the architecture's preserved registers. The condition mentioned in the previous sentence is that the low-level assembly language interrupt routines don't modify the preserved registers. The handlers usually call a higher-level C routine. The preserved registers are then saved on the stack by the compiler generated code of the higher-level function. In HelenOS, several architectures can be compiled with this optimization.
Although the kernel does not do any floating point arithmetics[5], it must protect FPU context of userspace threads against destruction by other threads. Moreover, only a fraction of userspace programs use the floating point unit. HelenOS contains a generic framework for switching FPU context only when the switch is forced (i.e. a thread uses a floating point instruction and its FPU context is not loaded in the processor).
The last member of the context family is the memory management context. It includes memory management registers that identify address spaces on hardware level (i.e. ASIDs and page tables pointers).
The scheduler, but also other pieces of the kernel, make heavy use
of synchronous context switches, because it is a natural vehicle not
only for changes in control flow, but also for switching between two
kernel stacks. Two functions figure in a synchronous context switch
implementation: context_save() and
context_restore(). Note that these two functions break the
natural perception of the linear C code execution flow starting at
function's entry point and ending on one of the function's exit
points.
When the context_save() function is called, the
synchronous context is saved in a memory structure passed to it. After
executing context_save(), the caller is returned 1 as a
return value. The execution of instructions continues as normally until
context_restore() is called. For the caller, it seems like
the call never returns[6]. Nevertheless, a synchronous register context, which is
saved in a memory structure passed to context_restore(), is
restored, thus transfering the control flow to the place of occurrence
of the corresponding call to context_save(). From the
perspective of the caller of the corresponding
context_save(), it looks like a return from
context_save(). However, this time a return value of 0 is
returned.
A thread is the basic executable entity with some code and a stack. While the code, implemented by a C language function, can be shared by several threads, the stack is always private to each instance of the thread. Each thread belongs to exactly one task through which it shares address space with its sibling threads. Threads that execute purely in the kernel don't have any userspace memory allocated. However, when a thread has ambitions to run in userspace, it must be allocated a userspace stack. The distinction between the purely kernel threads and threads running also in userspace is made by refering to the former group as to kernel threads and to the latter group as to userspace threads. Both kernel and userspace threads are visible to the scheduler and can become a subject of kernel preemption and thread migration anytime when preemption is not disabled.
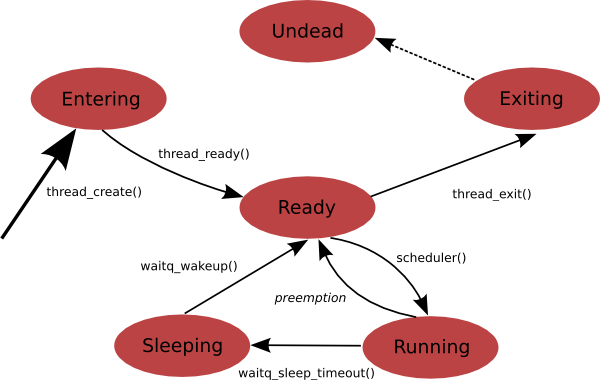
Thread States. In each moment, a thread exists in one of six possible thread
states. When the thread is created and first inserted into the
scheduler's run queues or when a thread is migrated to a new processor,
it is put into the Entering state. After some time
elapses, the scheduler picks up the thread and starts executing it. A
thread being currently executed on a processor is in the
Running state. From there, the thread has three
possibilities. It either runs until it is preemtped, in which case the
state changes to Ready, goes to the
Sleeping state by going to sleep or enters the
Exiting state when it reaches termination. When the
thread exits, its kernel structure usually stays in memory, until the
thread is detached by another thread using thread_detach()
function. Terminated but undetached threads are in the
Undead state. When the thread is detached or
detaches itself during its life, it is destroyed in the
Exiting state and the Undead
state is not reached.
Pseudo Threads. HelenOS userspace layer knows even smaller units of execution. Each userspace thread can make use of an arbitrary number of pseudo threads. These pseudo threads have their own synchronous register context, userspace code and stack. They live their own life within the userspace thread and the scheduler does not have any idea about them because they are completely implemented by the userspace library. This implies several things:
pseudothreads schedule themselves cooperatively within the time slice given to their userspace thread,
pseudothreads share FPU context of their containing thread and
all pseudothreads of one userspace thread block when one of them goes to sleep.
There is an array of several run queues on each processor. The current version of HelenOS uses 16 run queues implemented by 16 doubly linked lists. Each of the run queues is associated with thread priority. The lower the run queue index in the array is, the higher is the priority of threads linked in that run queue and the shorter is the time in which those threads will execute. When kernel code wants to access the run queue, it must first acquire its lock.
The scheduler is invoked either explicitly when a thread calls the
scheduler() function (e.g. goes to sleep or merely wants to
relinquish the processor for a while) or implicitly on a periodic basis
when the generic clock interrupt preempts the current thread. After its
invocation, the scheduler saves the synchronous register context of the
current thread and switches to its private stack. Afterwards, a new
thread is selected according to the scheduling policy. If there is no
suitable thread, the processor is idle and no thread executes on it.
Note that the act of switching to the private scheduler stack is
essential. If the processor kept running using the stack of the
preempted thread it could damage it because the old thread can be
migrated to another processor and scheduled there. In the worst case
scenario, two execution flows would be using the same stack.
The scheduling policy is implemented in the function
find_best_thread(). This function walks the processor run
queues from lower towards higher indices and looks for a thread. If the
visited run queue is empty, it simply searches the next run queue. If it
is known in advance that there are no ready threads waiting for
execution, find_best_thread() interruptibly halts the
processor or busy waits until some threads arrive. This process repeats
until find_best_thread() succeeds.
After the best thread is chosen, the scheduler switches to the thread's task and memory management context. Finally, the saved synchronous register context is restored and the thread runs. Each scheduled thread is given a time slice depending on its priority (i.e. run queue). The higher priority, the shorter timeslice. To summarize, this policy schedules threads with high priorities more frequently but gives them smaller time slices. On the other hand, lower priority threads are scheduled less frequently, but run for longer periods of time.
When a thread uses its entire time slice, it is preempted and put back into the run queue that immediately follows the previous run queue from which the thread ran. Threads that are woken up from a sleep are put into the biggest priority run queue. Low priority threads are therefore those that don't go to sleep so often and just occupy the processor.
In order to avoid complete starvation of the low priority threads, from time to time, the scheduler will provide them with a bonus of one point priority increase. In other words, the scheduler will now and then move the entire run queues one level up.
Normally, for the sake of cache locality, threads are scheduled on
one of the processors and don't leave it. Nevertheless, a situation in
which one processor is heavily overloaded while others sit idle can
occur. HelenOS deploys special kernel threads to help mitigate this
problem. Each processor is associated with one load balancing thread
called kcpulb that wakes up regularly to see whether its
processor is underbalanced or not. If it is, the thread attempts to
migrate threads from other overloaded processors to its own processor's
run queues. When the job is done or there is no need for load balancing,
the thread goes to sleep.
The balancing threads operate very gently and try to migrate low
priority threads first; one kcpulb never takes from one
processor twice in a row. The load balancing threads as well as threads
that were just stolen cannot be migrated. The kcpulb
threads are wired to their processors and cannot be migrated whatsoever.
The ordinary threads are protected only until they are
rescheduled.