
Scalable Concurrent Hash Table
- GSoC 2012, ticket #398
- mentor: Jakub Jermar
- student: Adam Hraska
- repository: lp:~adam-hraska+lp/helenos/rcu/
- benchmarking repository: lp:~adam-hraska+lp/helenos/cht-bench/
The goal of the project is to create a scalable concurrent resizable hash table (CHT):
- scalable = performance improves with added cpus
- concurrent = the table allows parallel access from multiple threads/cpus preferably without blocking
- resizable = the table grows and shrinks automatically as item are added or removed from it
Moreover, the table must be suitable to replace the current global page hash table in the kernel. Optionally, it may be ported to user space as well.
Current Status
Todos: *
Implementation
CHT Algorithm
RCU Algorithms
Testing
The CHT replies on working atomic operations, SMP calls (ie IPIs), RCU and the system work queue. In order to test these out, pull and build the source code (eg on x86-64 machines):
bzr checkout lp:~adam-hraska+lp/helenos/rcu/ make PROFILE=amd64
Boot HelenOS with eg 4 CPUs in QEMU:
qemu-system-x86_64 -cdrom image.iso -smp4
Once fully operational, switch to the kernel console by pressing F12 (or typing kcon in the shell). You can then finally run the following relevant tests:
test atomic1 test smpcall1 test workqueue test rcu1 test cht
Neither of the tests should panic, crash, leak memory, loop infinitely, or report errors. The only test workqueue reports an error which is however expected and marked appropriately with line Stress testing a custom queue. Stops prematurely. Errors are expected.
You may be interested in runtime statistics gathered by RCU or the system work queue. Run these commands in the kernel console:
rcu workq
Benchmarks
In order to benchmark the CHT or RCU implementation, pull sources of the benchmarking branch and build the code in a release build (ie clear the debug build option):
bzr checkout lp:~adam-hraska+lp/helenos/cht-bench/ make PROFILE=amd64 make config # this is where you have to clear the debug build option make
Boot HelenOS in QEMU with eg 4 CPUs and list the available benchmarks in the kernel console with the chtbench command:
qemu-system-x86_64 -cdrom image.iso -smp 4 / # kcon kconsole> chtbench 0 0 0
Results
The following results were obtained by benchmarking r1589 on Core™ i7 CPU 920 @ 2.67GHz (4 cores, each with 2 HyperThreads), running a release build (with networking):
contrib/conf/net-qe.sh e1k -smp 4
Each benchmark run consists of repeating a certain operation in a loop for 10 seconds
on the specified number of cpus (ie individual threads wired to these cpus).
Benchmarks were repeated as many times as needed (between 10 and 20 consecutive
runs) in order to obtain a confidence interval of the number of completed operations
within about 1% of the average number of completed operations of the runs. The following
figures include error bars depicting a single standard deviation of the completed number
of operations in a single run (ie it is not the SD of the mean, aka standard error).
However the estimated SD is typically below 1-2% of the mean (ie tiny) and therefore not
visible in the figures without zooming ![]() .
.
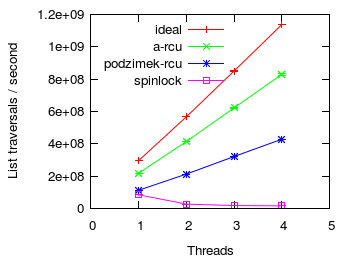
RCU read side scalability

First, we examine the overhead of rcu read sections compared to acquiring a spinlock.
The figure above shows the number of traversals of a five element immutable list
depending on the number of threads/cpus used. More is better ![]() .
.
- ideal - the list was accessed without any synchronization whatsoever
- a-rcu - each list traversal was protected by A-RCU
- podzimek-rcu - protected by the preemptible modification of Podzimek's RCU
- spinlock - guarded by an ordinary preemption disabling spinlock
A-RCU fares the best and has optimal scaling. On the other side, spinlock presents negative scaling (ie the more cpus you throw at it, the slower it is). Podzimek's RCU scales perfectly but has a greater base cost compared to A-RCU. In particular, Podzimek-RCU's base cost is on par with a spinlock when running on a single cpu while A-RCU's base cost is significantly lower than both Podzimek-RCU's and spinlock base cost.
To reproduce these results, switch to the kernel console and run:
chtbench 2 1 0 -w chtbench 2 2 0 -w chtbench 2 3 0 -w chtbench 2 4 0 -w chtbench 3 1 0 -w chtbench 3 2 0 -w chtbench 3 3 0 -w chtbench 3 4 0 -w chtbench 4 1 0 -w chtbench 4 2 0 -w chtbench 4 3 0 -w chtbench 4 4 0 -w
Then build with Podzimek-RCU and rerun:
chtbench 3 1 0 -w chtbench 3 2 0 -w chtbench 3 3 0 -w chtbench 3 4 0 -w
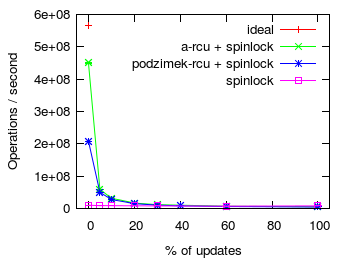
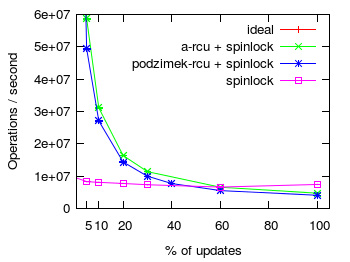
RCU write side overhead


Second, we examine the overhead of rcu writers (ie invoking rcu_call() and processing the callback in the background)
compared to acquiring a spinlock. The figure above shows the number of traversals
or updates of a five element list with an increasing percentage of updates.
The benchmark ran in 4 threads/CPUs. In each iteration each thread selected at random
whether to walk the entire list or to replace an item in the list (ie to update the
list). All items were preallocated. More is better ![]() . The figure on the right
details the effects of increasing the update percentage by leaving out the data point for 0% updates.
. The figure on the right
details the effects of increasing the update percentage by leaving out the data point for 0% updates.
- ideal - the list was accessed without any synchronization whatsoever on a single cpu; and the result multiplied by the number of cpus (ie 4)
- a-rcu + spinlock - each list traversal and update was protected by A-RCU; concurrent updates
were synchronized by means of a spinlock, but removed items were freed via
rcu_call() - podzimek-rcu + spinlock - same as a-rcu but protected by preemptible version of Podzimek's RCU
- spinlock - guarded by an ordinary preemption disabling spinlock
When the update fraction is small, RCU protected list traversals and modifications significantly outperform a spinlock guarded list. However, as the percent of updates increases the cost of acquiring a spinlock to modify the list quickly begins to dominate. In the case of RCU protected lists, updating a list involves not only locking a spinlock but also posting and rcu callback. Therefore, protecting an often modified list with a spinlock eventually outperforms RCU guarded lists. The cross over point is around 40% and 60% of updates for Podzimek's RCU and A-RCU respectively. Again A-RCU fare a bit better than the preemptible version of Podzimek's RCU.
To reproduce these results, switch to the kernel console and run:
chtbench 6 1 0 -w chtbench 7 4 0 -w chtbench 7 4 5 -w chtbench 7 4 10 -w chtbench 7 4 20 -w chtbench 7 4 30 -w chtbench 7 4 40 -w chtbench 7 4 60 -w chtbench 7 4 100 -w chtbench 8 4 0 -w chtbench 8 4 5 -w chtbench 8 4 10 -w chtbench 8 4 20 -w chtbench 8 4 30 -w chtbench 8 4 40 -w chtbench 8 4 60 -w chtbench 8 4 100 -w
Then rebuild with Podzimek-RCU and rerun:
chtbench 7 4 0 -w chtbench 7 4 5 -w chtbench 7 4 10 -w chtbench 7 4 20 -w chtbench 7 4 30 -w chtbench 7 4 40 -w chtbench 7 4 60 -w chtbench 7 4 100 -w
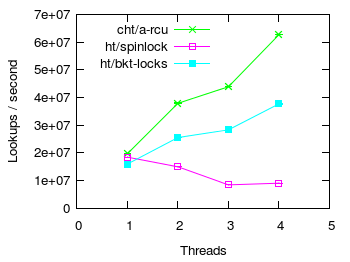
Hash table lookup scalability

In this section we compare lookup scalability of CHT with ordinary spinlock guarded hash tables. The test consists of searching for keys in tables with load factor 4 (ie 4 items/bucket on average). Half of all lookups searched for keys not present in the table. Moreover, all items were inserted into the tables before the benchmark started.
In the figure above:
- ht/spinlock - represents the original non-resizible kernel hash table with 127 buckets and guarded by a single global spinlock.
- ht/bktlock - same as ht/spinlock but protects each bucket with a separate spinlock.
- cht/a-rcu - CHT protected by A-RCU, uses 128 buckets.
Note that CHT was set up with the resize triggering load factor high enough for CHT to never resize. However, CHT was still tracking the number of items in the table and still checking if it should resize — quite unlike the spinlock protected tables that are not resizible and therefore do not need to track the number of elements nor check if a resize is in order.
What is more, CHT and HTs use different hash functions. While CHT mixes user supplied hashes to produce a good hash, HTs divide user supplied hashes by a prime number and use the remainder as the final hash. This influences both the distribution of items in buckets as well as the time to actually compute a hash. Keys were selected to favor traditional HTs which achieved an optimal item distribution (exactly 4 per each bucket). On the other hand, in CHT buckets contained from 0 to 9 items. Furthermore, the hash mixing function used by CHT in rev1589 appears to be slightly slower (~10% slower) than dividing by a prime.
As expected, a HT protected by a single spinlock scales negatively. On the other hand, a HT with one spinlock/bucket scales fairly well but is significantly slower than CHT. CHT performs slightly better than both HTs in the base case of running on a single cpu.
To reproduce these results, switch to the kernel console and run:
chtbench 13 1 0 -w chtbench 13 2 0 -w chtbench 13 3 0 -w chtbench 13 4 0 -w chtbench 14 1 0 -w chtbench 14 2 0 -w chtbench 14 3 0 -w chtbench 14 4 0 -w chtbench 15 1 0 -w chtbench 15 2 0 -w chtbench 15 3 0 -w chtbench 15 4 0 -w
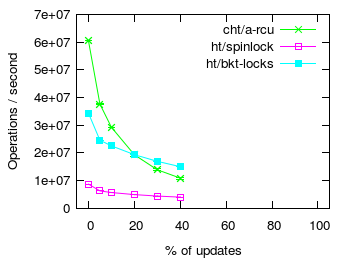
Hash table update overhead

To reproduce these results, switch to the kernel console and run:
chtbench 10 4 0 -w chtbench 10 4 5 -w chtbench 10 4 10 -w chtbench 10 4 20 -w chtbench 10 4 30 -w chtbench 10 4 40 -w chtbench 11 4 0 -w chtbench 11 4 5 -w chtbench 11 4 10 -w chtbench 11 4 20 -w chtbench 11 4 30 -w chtbench 11 4 40 -w chtbench 12 4 0 -w chtbench 12 4 5 -w chtbench 12 4 10 -w chtbench 12 4 20 -w chtbench 12 4 30 -w chtbench 12 4 40 -w
Final notes
Attachments (5)
- r1589-list-read.png (17.4 KB ) - added by 14 years ago.
- r1589-list-upd.png (16.6 KB ) - added by 14 years ago.
- r1589-ht-lookup.png (13.2 KB ) - added by 14 years ago.
- r1589-ht-upd.png (14.2 KB ) - added by 14 years ago.
- r1589-list-upd-trim.png (18.5 KB ) - added by 14 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip