
Opened 15 years ago
Closed 10 years ago
#389 closed defect (worksforme)
Devman crashes after repeated add/remove.
| Reported by: | Jan Vesely | Owned by: | |
|---|---|---|---|
| Priority: | major | Milestone: | 0.7.0 |
| Component: | helenos/srv/devman | Version: | mainline |
| Keywords: | malloc | Cc: | |
| Blocker for: | Depends on: | ||
| See also: | #384 |
Description
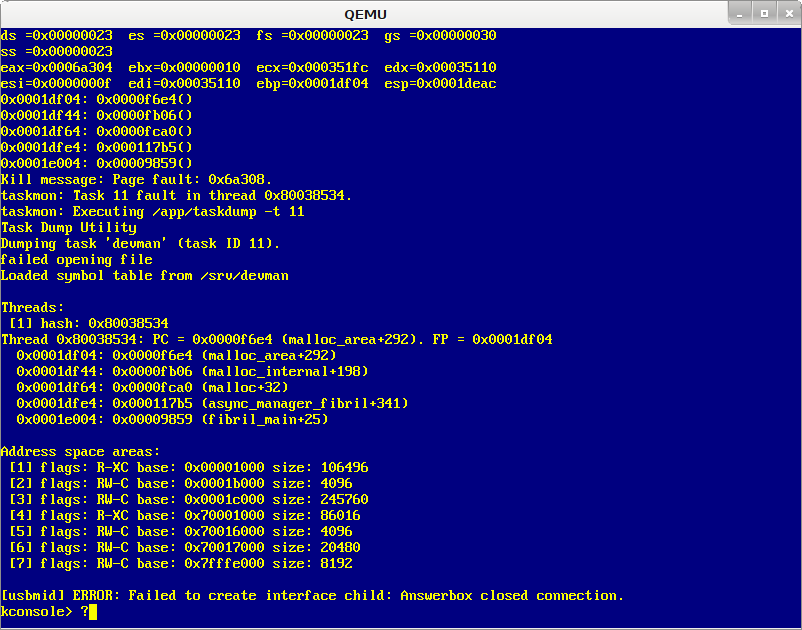
Testing USB unplug functionality, after 64 mouse plug/unplug cycles devman crashes with stack-trace:
malloc_area+292
malloc_internal+198
malloc+32
async_manager_fibril+341
fibril_main+25
Attachments (6)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (23)
by , 15 years ago
| Attachment: | Screenshot-mainline.png added |
|---|
comment:1 by , 14 years ago
Could you please provide a small how-to reproduce? I tried to issue the usb_add/del commands from the QEMU monitor, but the whole QEMU would usually coredump afterwards, complaining about a failed assertion on some object's reference count.
comment:2 by , 14 years ago
I used qemu usb_add/del in my experiment. I would repeatedly add/remove single device. qemu has problems dealing with things like removing USB hub with attached devices, but using single device add/remove worked until devman crashed.
comment:3 by , 14 years ago
| Keywords: | malloc added |
|---|
Interestngly, removing a hub with an attached devices was survived by QEMU 1.0.1. On the other hand, I have another problem when trying to reproduce this. After a couple of iterations, QEMU would change the bus.device address of the device. Here is what I am doing:
(qemu) usb_add mouse (qemu) usb_del 0.1
comment:4 by , 14 years ago
Jano, could you try to reproduce it for one more time? We seem to be unable to reproduce this. Btw, do you use any special timing between the usb_add and usb_del commands? Many thanks. Jakub
comment:5 by , 14 years ago
I can reproduce on latest mainline and qemu kvm 1.0.1
Number of add/removes is 87.
usb_add mouse
usb_del 0.1
repeat until crash
trigers the bug for me
comment:6 by , 14 years ago
sry for double attachment, server has been acting weird for me today.
I do not use any special timing between add/del, just hit double up arrow and enter as fast as I can ![]()
qemu only sets bus id, device id is USB address assigned by helenos USB stack,
with one device it will reuse address 1.
if a qemu device is identified as 0.0 it means it has no address assigned. it is either:
a) too early after usb_add and the device has not been initialized yet (I doubt I can hit this with kvm)
b) it will never be initialized.
In fact b) is one of the ways this bug manifests. I repeat add/del until I hit "could not delete USB device '0.1'", and "info usb" shows device 0.0. I then switch to HelenOS and see devman trace.
comment:7 by , 14 years ago
The crash as captured by the screenshot occurred here:
11f50: 4c 01 ce add %r9,%rsi 11f53: 49 39 f4 cmp %rsi,%r12 11f56: 76 48 jbe 11fa0 <malloc_area+0x150> 11f58: 81 7e 18 01 01 ef be cmpl $0xbeef0101,0x18(%rsi) 11f5f: 0f 85 b7 02 00 00 jne 1221c <malloc_area+0x3cc> 11f65: 4c 8b 0e mov (%rsi),%r9 11f68: 49 89 f0 mov %rsi,%r8 11f6b: 4a 8d 44 0e f0 lea -0x10(%rsi,%r9,1),%rax 11f70: 81 78 08 02 02 ef be cmpl $0xbeef0202,0x8(%rax) <==== CRASH
Translated into C:
static void block_check(void *addr)
{
heap_block_head_t *head = (heap_block_head_t *) addr;
malloc_assert(head->magic == HEAP_BLOCK_HEAD_MAGIC);
heap_block_foot_t *foot = BLOCK_FOOT(head);
malloc_assert(foot->magic == HEAP_BLOCK_FOOT_MAGIC); <==== CRASH
Note that block_check() was called from malloc_area(). Header of the block was still in the mapped area, while the footer was out of any existing address space area, as depicted on the screenshot and as evidenced by the rsi + r9 sum.
comment:8 by , 14 years ago
I am attaching a simple script (batch) that reproduces the bug in an semi-automated way (one keypress is needed after HelenOS has finished booting).
The command line is as follows:
$ ./batch | (qemu-system-x86_64 --enable-kvm -cdrom image.iso -usb -monitor stdio)
by , 14 years ago
| Attachment: | devman.tar.bz2 added |
|---|
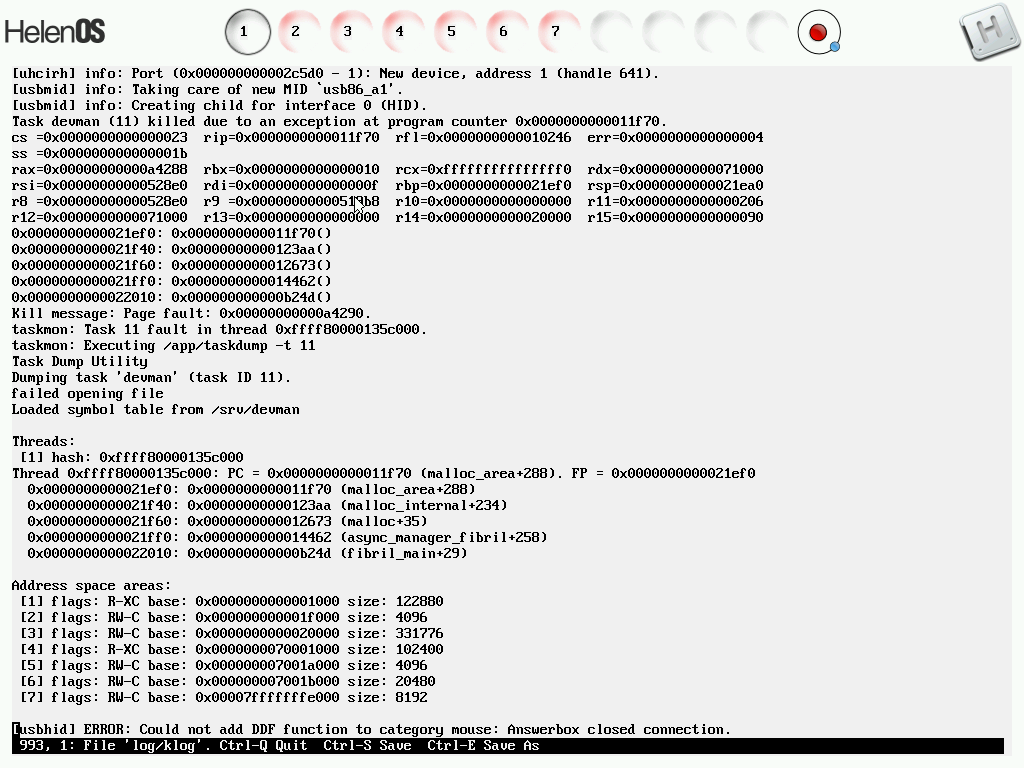
Two devman core dumps and the devman binary taken when this issue was reproduced on ia32.
comment:9 by , 14 years ago
I've just uploaded devman.tar.bz2 which contains two ia32 coredumps showing the two possible manifestations of this bug on ia32.
comment:10 by , 14 years ago
| See also: | → #384 |
|---|
by , 14 years ago
| Attachment: | devman2.tar.bz2 added |
|---|
More ia32 coredumps, this time with source level debugging information.
comment:11 by , 14 years ago
I am wondering if this behavior, as documented by the attached core dumps, can be explained by #384.
comment:12 by , 14 years ago
| Milestone: | 0.5.0 → 0.5.1 |
|---|
Rescheduling this ticket to the next release. It is probably a duplicate of #384. Moreover, the issue is unlikely to be hit under normal workloads.
comment:13 by , 14 years ago
#384 has been fixed and I can still reproduce on current mainline (amd64).
comment:14 by , 12 years ago
Still reproducible with mainline,2259.
With all the fibril traces available to us, I noticed that the other fibrils (the ones that did not run at the time of the crash) were doing this:
- the majority (at least a dozen) were blocked in: devman_connection_driver() → async_get_call_timeout()
- one assign_driver_fibril, assign_driver_fibril() → async_driver()→add_device() → async_wait_for()
- one connection_fibril, connection_fibril() → devman_connection() → fibril_mutex_unlock() → failed_asserts+verybigoffset
- one async manager fibril, async_manager_fibril() → fibril_switch()
- one initial fibril, main() → fibril_switch()
comment:15 by , 11 years ago
| Milestone: | 0.6.0 → 0.7.0 |
|---|
comment:16 by , 10 years ago
mainline,2543 fixed a memory corruption caused by leaving deallocated (i.e. after function remove/offline) function nodes in the loc_functions hash table. The above issues appear to be no longer reproducible.
comment:17 by , 10 years ago
| Resolution: | → worksforme |
|---|---|
| Status: | new → closed |
qemu screen